Reward is Not Not Enough: AGI and Reward Maximization
So I chanced by this post on LessWrong titled “Reward is Not Enough”. It is a rebuttal to the arguments presented in the paper “Reward is Enough” by Silver et al, which hypothesises that intelligence and its associated attributes are a result of reward maximization of an agent acting in its environment. Given the popularity of the LessWrong Forum, the pseudo-persuasive appeal of the article aided by technical jargon and for the sake of rationality, the post merits a deeper examination. I think the post is somewhat ill-informed fear mongering. Here’s why:
The author’s summarization of the paper and assumption expressed in the last two paragraphs - that multi-component systems are not RL algorithms and are not covered by the original paper - is untrue. The kitchen robot example in Silver et. al. is multi component because you have multiple sensor modalities. Deepmind already works on/collaborates on multi component RL algorithms and they’re fairly frequent in literature so the view of RL the post is basing its logic on is too simplistic.
Secondly, here’s how I’d solve the three case studies with reward.
- The “conflict” in case study 1
How to make reward be greater when performance is poorer? No you don’t need two different networks with different reward signals. You can solve this “conflict” with a purely convex reward function where the derivative is higher farther away from goal state. That is, worse your singing, higher your reward with delta improvement in singing, hence practice becomes the action which maximizes future rewards.
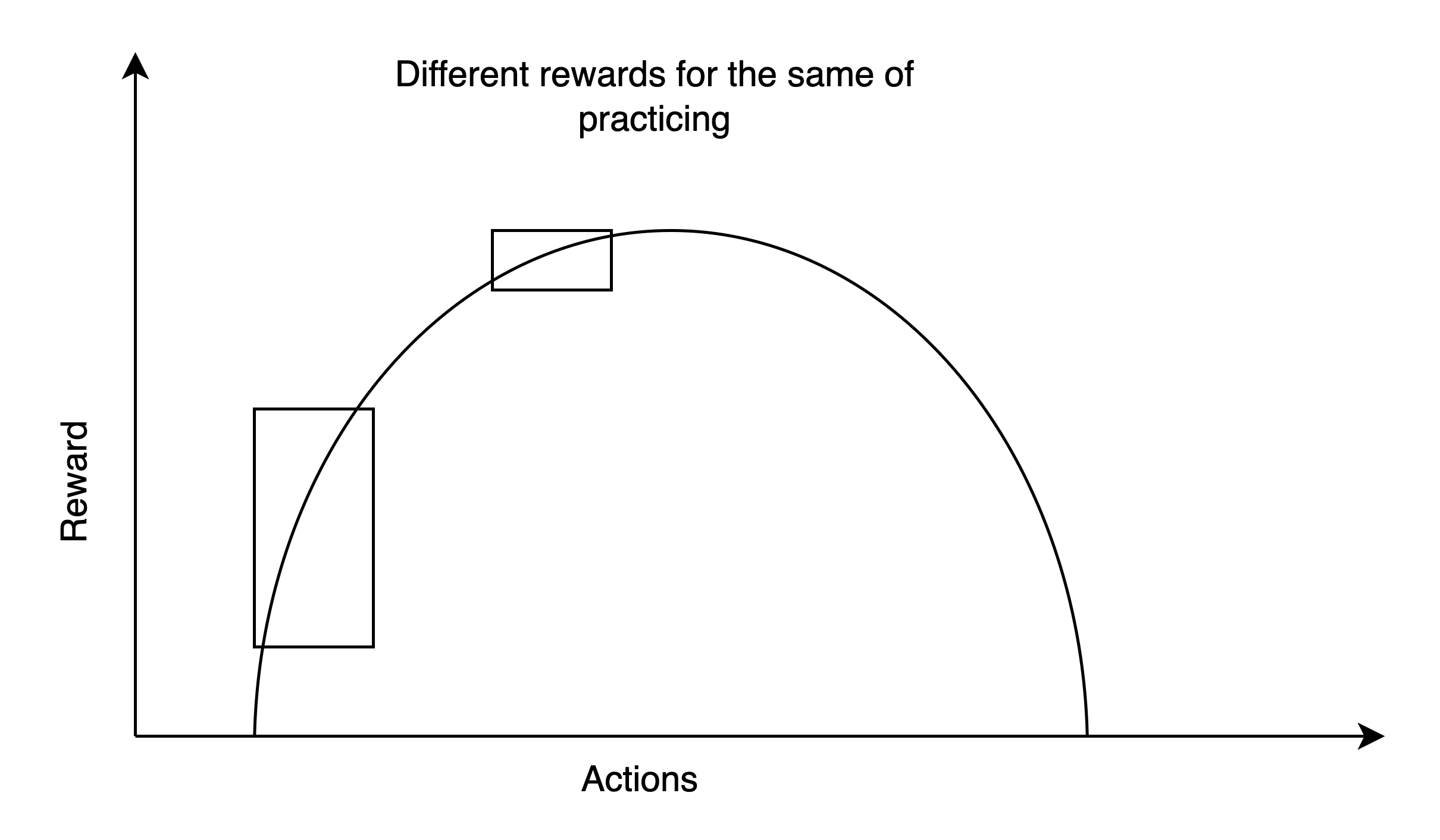
- The Hiking example
Wrong problem framing here. If the spider only scuttles and does no harm, keeping your eyes closed or misclassifying it is optimal if you get some reward from uninterrupted sleep. So there’s no problem if the hiker decides to do that. But if spider kills you on biting, and gives you a very high negative reward, both keeping eyes closed and misclassifying will be suboptimal actions in a converged action-value function approximation. So the problems he mentions(hiker sleeping, etc) are because of an underspecified reward function i.e. spider is scary but nonlethal.
- “Credit assignment problem”
Not a problem, already solved with backdrop. Variables that contribute to the final reward will get the updates because derivative of loss with respect to them will be higher. Variables that don’t matter don’t get the updates, because they won’t show up the loss differential.
- Well but there are supervisory training signals in the human brain
Humans are generally intelligent ( I think) but not optimal. Evolution is not supposed to be optimal but apparently it is sufficient to create us. Of course dopamine is the internal reward mechanism we use but if the objectives incentivized by dopamine conflict with objectives incentivized by environment specified reward - agent still fails. Example, death by drug overdose. So dopamine is not a training signal, only an approximation of the external reward function that incentivizes progression of your genes.
- Analysis paralysis
Also, at what level of abstraction will the author stop? Because while brain is composed of components with supervisory training signals, they are further composed of other components. Ultimately, they’re all composed of cells and nuclei which have their own training signals. Steven’s proposed design for AGI that breaks down components with multiple rewards doesn’t scale.
- Deceptive AGI that manipulates you
This is a classic case of underspecified reward function. There’s no need for separate word-choosing and solar-panel-making networks. A single large network that does both can be given a negative reward for manipulation to discourage manipulation and the relative importance of the manipulating and solar-panel-making can be expressed in terms of the magnitudes of the negative and positive rewards for the respective skills. If manipulation is absolutely bad, then that action should be infeasible and can be done with a theoretically infinite reward that ends the episode( but practically it’s not infeasible because INT_MAX or FLOAT_MAX are not infinite. May be enforce rejection sampling here.).
- Necessary and sufficient conditions
Oh by the way, human beings are intelligent and yet manipulate you to advance their agendas, so why is niceness/safety of other agents(humans here), fundamental to achieving general intelligence?
Also, if I may, posts that explain in complex English sentences and with trivilaised examples what could be expressed by a clean math equation is simply annoying; it is an infantilization of human intelligence. Most AI research is mathematical.
To summarize, the title of the paper “Reward is Enough” is not literal but that is understood. Of course you need data, infra, architecture adaptation and model complexity to capture Q value function complexity. But problems that the author, Steven Byrnes, mentions are not credible challenges to the hypothesis in the paper. Of course we won’t know if reward is enough until AGI is here, so it could still be wrong, but not for the reasons in the post.